Tratamento de dados de Escala Likert
Preliminares
Nosso objetivo é mostrar como fazer um tratamento preliminar de dados de escala do tipo Likert usando o R. Nosso caminho será:
-
Inicialmente, mostraremos como extrair os dados de um documento advindo do Ibex Farm, fazendo uma pequena limpeza nos dados de modo a torná-los mais palatáveis;
-
Em seguida, faremos uma breve investigação descritiva dos dados, mostrando como construir uma tabela com contagens e porcentagens para cada nível da escala e como visualizar esses dados com um gráfico útil para publicar essas informações;
-
Por fim, faremos uma análie desses dados com um modelo de regressão oridinal com o pacote
brms.
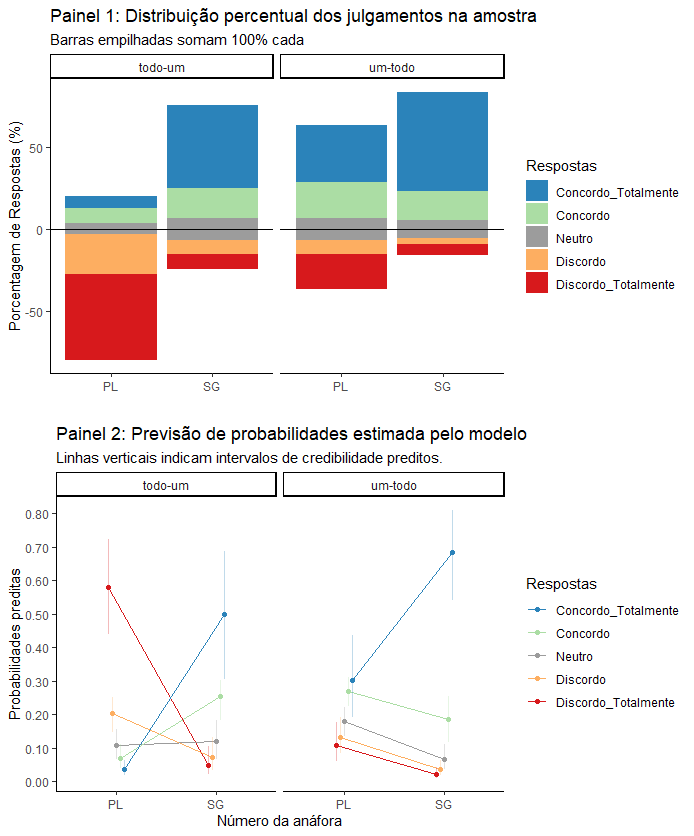
Ao final, você deve conseguir um resultado como esse:
Esse artigo assume que você conhece os comandos básicos do R, como manipular dados, como instalar e carregar pacotes além de outras funcionalidades semelhantes. Nosso objetivo não é dar informações detalhadas sobres interpretação dos dados, mas apenas ilustrar como investigá-los com o R.
O experimento
O experimento mensurava o julgamento de falantes em uma escala com 5 níveis, indo de 1 = discordo totalmente até 5 = concordo totalmente. Os fatores preditivos eram ordem dos quatificadores em uma sentença (um-todo e todo-um) e número de um pronome anafórico na sentença seguinte (singular e plural). Dois exemplos esquemáticos de frases são dados abaixo:
…mostrou uma camisa… para todo comprador…
…mostrou toda camisa… para um comprador…
Os dados usados nesse tutorial podem ser baixados aqui. Os nomes e e-mails dos participantes foram alterados para preservar suas identidades. Uma descrição mais detalhada do experimento pode ser encontrada aqui.
Carregando os dados de um arquivo ibex
O primeiro passo é instalar o pacote ibextor para acessar os dados do Ibex Farm. Se o comando install.packages("ibextor") não funcionar, sugerimos que você instale o pacote remotes e então faça a instalação diretamente do repositório do ibextor. A Documentação do pacote está disponível aqui.
install.packages("remotes")
remotes::install_github("antonmalko/ibextor")Carregando pacotes necessários para esse tutorial
require(stringr)
require(dplyr)
require(tidyr)
require(ibextor)Extraindo resultados de julgamento de aceitabilidade
Para começar, vamos usar a função get_results_aj para extrair os dados de nosso interesse. Observe que aj vem de acceptability judgment, que é o tipo de experimento feito no Ibex nesse caso. Se você estivesse extraindo outro tipo de dado, como de leitura automonitorada, a função seria outra. Consulte a documentação do pacote para esses casos. Vamos colocar esses dados num objeto de nome dados (você pode dar o nome que você quiser). Repare que você precisará colocar o PATH adequado no local onde está, no exemplo baixo, "/home/dados/...". Esse é o endereço no seu computador onde o arquivo está guardado, terminando com o nome do arquivo.
dados<-get_results_aj("/home/dados/Acadêmicos/Doutorado/EXPERIMENTOS_2021/EscalaLikert/Resultados.csv")Se você quiser, pode explorar essa tabela com as funções head, str, etc. Após essa inspeção, nós vamos limpá-la de algumas colunas que não nos interessam nela. Caso deseje entender o que estamos fazendo aqui, rode passo a passo o código abaixo:
dados<-dados %>%
select(-c(question, sentence, presentation_order, subj_uid)) %>% # Elimina colunas desnecessárias
filter(str_detect(type, "^e")) %>% # Filtra apenas as sentenças experimentais (começam com a letra "e")
separate(type, c("Ordem", "Num"), "[_]") %>% # Separa a coluna "type" (condições) nos fatores analisados (V. Independentes)
separate(Ordem, c("a", "Ordem"), "[.]") %>% # Separa o "e" inicial em uma coluna própria
select(-a) # Remove essa coluna inútilExtraindo os dados dos sujeitos
Para extrair os dados socioeconômicos dos sujeitos, basta usar a função get_subj_info, também do ibextor. No caso do experimento em questão, além do PATH onde o arquivo está armazenado (o mesmo usado anteriormente), vamos passar pela função o argumento form_name, já que nosso experimento tinha mais de um formulário. Vamos dar o nome de sujeitos a esses dados (como sempre, você pode dar o nome que achar melhor).
sujeitos<-get_subj_info("/home/dados/Acadêmicos/Doutorado/EXPERIMENTOS_2021/EscalaLikert/Resultados.csv",
form_name = "DadosPessoais") # Como há mais de um formulário, de qual deles extrair os dadosVamos agora fazer uma gambiarra aqui e criar uma coluna com os números de cada sujeito. Essa coluna precisa ter o mesmo nome (subj) da coluna sujeitos na tabela anterior. Além disso, ela será do tipo fator (factor), assim como a coluna subj da tabela anterior. Daí vamos juntar as duas tabelas com inner_join, de modo a ter as informações dos sujeitos, e, por fim, já que agora a coluna subj e nome são redundantes, vamos retirar a nome. Vamos fazer em três passos:
sujeitos$subj <- as.factor(seq.int(nrow(sujeitos)))
dados<-inner_join(dados, sujeitos)
dados<-dados %>%
select(-c(nome, contato)) # E também a coluna "contato" para garantir o sigilo dos sujeitosExtraindo informações necessárias
Feito isso, você pode extrair os dados que achar necessários, inclusive exportando essa tabela para fora do R para ser publicada em algum lugar. Vamos mostrar algumas possibilidades.
Primeiro, vamos salvar essa tabela externamente ao R em formato .csv. Nesse caso, ela será salva no seu working directory. Veja a função getwd e setwd para saber qual é o seu diretório de trabalho e como modificá-lo.
write.csv(dados, "dados_finais.csv")Vamos, além disso, filtar alguns sujeitos, digamos, que tenham sido instruídos a digitar seus nomes com uma informação (por exemplo: alunos provenientes da Universidade UERJ, que digitaram depois do nome UERJ).
sujeitos %>%
filter(str_detect(nome, "UERJ")) %>% # filtrar todos que tenham "UERJ"
write.csv("alunos_uerj.csv") # Exportar a tabelaOu vamos supor que você precise enviar uma mensagem, digamos, a cópia do TCLE, para todos os que deixaram seu e-mail cadastrado. Como todo e-mail tem @, vamos filtar por esse elemento:
sujeitos %>%
filter(str_detect(contato, "@")) %>%
write.csv("lista_emails.csv")Abordagem descritiva dos dados
Os pacotes necessários a essa etapa são:
require(ggplot2)
require(dplyr)
require(RColorBrewer)
require(tidyr)
require(scales)Filtragens iniciais
Se você quiser (e achamos que deveria), pode dar uma olhada nos dados com a função str. A partir disso, vamos fazer algumas tranformações nos dados, transformando as colunas do tipo caractere (chr) em funções do tipo fator (Factor). A coluna answer será, por sua vez, do tipo ordenada (ordered factor), já que é a resposta dada à escala do tipo Likert.
dados<-dados %>%
mutate_if(is.character, as.factor) %>%
mutate(answer=as.ordered(answer))Feito isso, vamos filtar os sujeitos que não atendem ao critério “Falante nativo” (idioma == nao). Se você investigar com mais atenção esses dados, perceberá que todos os sujeitos atendem ao critério “escolaridade” (Ensino Médio Completo), então não vamos tirar nada com base nessa coluna. No entanto, ao investigar a construção dos estímulos, percebemos um problema com o item de número 11, então vamos eliminá-lo completamente também.
dados<-dados %>%
filter(idioma %in% "sim") %>% # Seleciona apenas o que contém "sim"
filter(!item == 11) # Seleciona apenas o que não contém (`!=`) 11.Abordagem descritiva por si
Em primeiro lugar, vamos deixar claro que o modo de fazer o gráfico foi primeiramente disponibilizado neste endereço. Vale a pena dar uma conferida por lá.
Antes de tudo, vamos calcular a contagem dos valores brutos, colocar isso em uma tabela no formato horizontal, mudar o nome das colunas de modo que os números da escala (1 a 5) recebem suas categorias correspondentes (de “discordo totalmente” até “concordo totalmente”):
contag <- dados %>%
group_by(Ordem, Num, answer) %>%
tally() %>%
group_by(Ordem, Num) %>%
spread(answer, n)
colnames(contag) <- c("Ordem", "Num", "Discordo_Totalmente", "Discordo", "Neutro", "Concordo", "Concordo_Totalmente")
write.csv(contag, "contagens.csv")Agora vamos calcular as porcentagens correspondentes e colocar em uma tabela de formato horizontal.
porc_horiz <- dados %>%
group_by(Ordem, Num, answer) %>%
tally() %>%
mutate(perc=n/sum(n)*100) %>%
dplyr::select(-n) %>%
group_by(Ordem, Num) %>%
spread(answer, perc)
colnames(porc_horiz) <- c("Ordem", "Num", "Discordo_Totalmente", "Discordo", "Neutro", "Concordo", "Concordo_Totalmente")
write.csv(porc_horiz, "porcentagens.csv")> porc_horiz
# A tibble: 4 x 7
# Groups: Ordem, Num [4]
Ordem Num Discordo_Totalmente Discordo Neutro Concordo Concordo_Totalmente
<fct> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 todo-um PL 52.3 24.2 6.71 9.06 7.72
2 todo-um SG 9.18 8.50 13.6 18.0 50.7
3 um-todo PL 21.4 8.44 13.6 21.4 35.1
4 um-todo SG 6.69 4.01 11.0 17.7 60.5Esses já são nossos dados finais, mas, para colocá-los em um gráfico de barras empilhadas, vamos precisar fazer algumas manipulações com eles. O princípio será o seguinte: dividir os dados ao meio, de modo que um conjunto contenha os dados da parte baixa da escala, ou seja, discordo totalmente e discordo; e outro conjunto contenha os dados da parte de cima da escala, ou seja, concordo e concordo totamente. Além disso, quanto ao meio da escala (o julgamento Neutro), temos que colocar metade dele abaixo e metade dele acima da escala.
Primeiro, vamos dividir o meio da escala (os julgamentos “Neutro”):
dados_meio <- porc_horiz %>%
mutate(c1 = Neutro / 2,
c2 = Neutro / 2) %>%
dplyr::select(Ordem, Num, Discordo_Totalmente, Discordo, c1, c2, Concordo, Concordo_Totalmente) %>%
gather(key = answer, value = perc, 3:8)Agora vamos separar a escala em dois conjuntos, o “alto” e o “baixo” (não deixe de ler os comentários no código, pois há uma inversão que pode ser um pouco confusa):
meio_alto <- dados_meio %>%
filter(answer %in% c("Concordo_Totalmente", "Concordo", "c2")) %>%
mutate(answer = factor(answer, levels = c("Concordo_Totalmente", "Concordo", "c2"))) # Níveis na ordem normal!
meio_baixo <- dados_meio %>%
filter(answer %in% c("c1", "Discordo", "Discordo_Totalmente")) %>%
mutate(answer = factor(answer, levels = c("Discordo_Totalmente", "Discordo", "c1"))) # Níveis na ordem inversa!Com isso, você já poderia plotar os dados com o ggplot2, mas vamos estabelecer uma paleta de cores mais interessante para os dados. Você pode investigar as diversas paletas de cores do pacote RColorBrewer apenas buscando no Google pelo nome do pacote.
legend_pal <- brewer.pal(name = "Spectral", n = 5) # Usar, do pacote RColorBrewer, a paleta de cores "spectral", com 5 cores
legend_pal<-c("#2B83BA", "#ABDDA4", "#FFFFBF", "#FFFFBF", "#FDAE61", "#D7191C") # Duplica a cor do meio manualmente
legend_pal <- gsub("#FFFFBF", "#9C9C9C", legend_pal) # Substituir a cor do meio por um cinza
names(legend_pal) <- c("Concordo_Totalmente", "Concordo", "c1", "c2", "Discordo", "Discordo_Totalmente") # Atribuir nomes às corescoord_flip se quiser ver o gráfico por um outro ângulo.
ggplot() +
geom_bar(data = meio_alto, aes(x = Num, y=perc, fill = answer), stat="identity") +
geom_bar(data = meio_baixo, aes(x = Num, y=-perc, fill = answer), stat="identity") +
geom_hline(yintercept = 0, color =c("black")) +
facet_wrap(~Ordem)+
scale_fill_manual(values = legend_pal,
breaks = c("Concordo_Totalmente", "Concordo", "c2", "Discordo", "Discordo_Totalmente"),
labels = c("Concordo_Totalmente", "Concordo", "Neutro", "Discordo", "Discordo_Totalmente")) +
scale_y_continuous(breaks = seq(from=-100, to=100, by=20))+
#coord_flip() +
labs(x = "", y = "Porcentagem de Respostas (%)", fill="Respostas") +
ggtitle("Painel 1: Distribuição percentual dos julgamentos na amostra",
subtitle = "Barras empilhadas somam 100% cada") +
theme_classic()Se você quiser, pode fazer o mesmo gráfico para os itens ou mesmo para cada um dos sujeitos. Para isso, basta repetir os passos, desde a produção da tabela de contagens e porcentagens. É um bom exercício para praticar.
Ajustando um modelo de regressão ordinal aos dados
Os pacotes necessários a essa etapa são:
require(brms)
require(sjPlot)Como a variável resposta desse experimento é de natureza ordinal, ou seja, valores ordenados em uma escala, o modo adequado de analisá-la é com um modelo de regressão ordinal. Há alguns pacotes no R que fazem esse serviço. O mais comum deles é o pacote MASS, que tem a função polr para esse tipo de dado. Um bom exemplo de como fazer uma análise desse tipo pode ser encontrada neste endereço. O problema é que essa função não nos permite incluir fatores aleatórios (“random factors”) no modelo, e, no caso em questão, temos dois fatores aleatórios (sujeitos e itens).
Uma boa solução, então, seria usar o pacote ordinal. No entanto, esse pacote não nos fornece uma importante ferramenta, que o pacote MASS fornecia, que é a “previsão de probabilidades”. Se quiser saber como usar esse pacote, você pode dar uma olhada neste tutorial.
A saída parece ser, portanto, apelar para a estratégia de “usar uma bazuca para matar coelhos” e tentar analisar os dados em uma abordagem bayesiana com o pacote brms, cuja documentação pode ser encontrada aqui. Há um bom tutorial do próprio autor disponível aqui.
Ajustando um modelo máximo
Primeiro, vamos seguir as recomendações de Baar et. al. (2013) e ajustar um modelo máximo aos dados.
Mas antes, verifiquemos quais os contrastes dos dados:
contrasts(dados$Num)
contrasts(dados$Ordem)E mudemos o nível-base para “um-todo” para facilitar a comparação entre as condições “um-todo” SG x PL
dados$Ordem<-relevel(dados$Ordem, ref = "um-todo")Daí ajustamos o modelo. Tenha paciência porque isso vai demorar… bastante… Vamos ajustar um modelo logístico cumulativo.
m2 <- brm(answer ~ Ordem*Num + (1+Ordem*Num|subj)+(1+Ordem*Num|item), data = dados,
family = cumulative("logit"))
summary(m2)Feito isso, vamos montar uma tabela com os dados dos fatores fixos e respectivos intervalos de credibilidade:
# Extrai os dados
fixos.m<-fixef(m2)[5:7,]
# Preparar um data.frame com esses dados
colnames(fixos.m)<-c("Estimativas", "Est.Error", "lower", "upper")
fixos.m<-as.data.frame(fixos.m)fixos.m<-fixos.m %>%
mutate(OddsRatio=exp(Estimativas)) %>%
mutate(Probs=OddsRatio/(1 + OddsRatio)*100)Com isso, se você achar necessário, já pode fazer um gráfico para publicação.
fixos.m %>%
ggplot(aes(x=reorder(rownames(fixos.m), Estimativas),
y=Estimativas))+
geom_hline(yintercept = 0, linetype = "dashed", color = "grey")+
geom_errorbar(aes(ymin=lower, ymax=upper), width=.0,
position=position_dodge(.9))+
geom_point(color="orange")+
scale_x_discrete(labels=c("ORDEM: todo_um", "NÚMERO: Singular", "INTERAÇÃO: ordem x número"))+ # ao mudar a ordem é preciso mudar aqui
labs(y = "LogOdds", x = "") +
ggtitle("Coeficientes estimados e intervalos de credibilidade (0.95)",
subtitle = "Intervalos que não contêm zero são estatisticamente significativos") +
coord_flip()+theme_classic()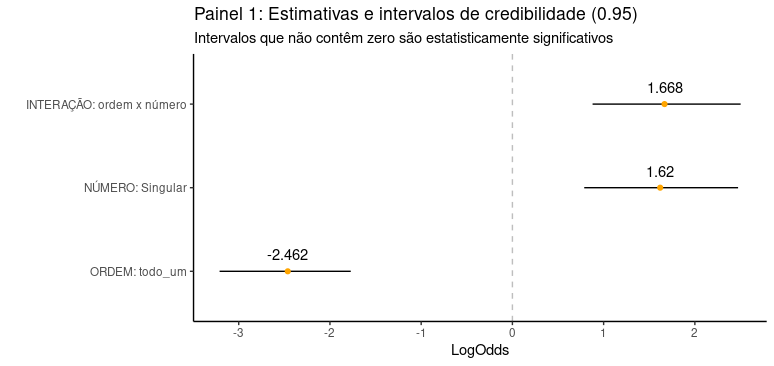
Calculando a previsão de probabilidades
Em geral, a menos que você seja um entendedor do assunto (e, portanto, nem estaria por aqui), esses coeficientes são difíceis de interpretar e, para dados ordinais, o melhor é extrair do modelo a “previsão de probabilidades” para os dados utilizados ou para um novo conjunto de dados. Vamos usar para isso o pacote sjPlot (documentação aqui) e investigar os chamados “efeitos marginais”.
model_data<-get_model_data(m2,
type = "pred",
terms = c("Ordem", "Num"),
ci.lvl = .95)Observe que com isso já temos os dados de que precisamos, mas, para plotá-lo em um gráfico customizável, vamos arrancar esses dados daí e colocá-los em uma data.frame “normal”, digamos assim.
model_data<-data.frame(ordem = model_data$x,
num = model_data$group,
Respostas = model_data$response.level,
Probabilidades = model_data$predicted,
lower = model_data$conf.low,
upper = model_data$conf.high)
model_data$ordem<-c(rep("um-todo", 10), rep("todo-um", 10))
model_data$ordem<-as.factor(model_data$ordem)Com isso, podemos finalmente plotar o gráfico, sem os intervalos de credibilidade (mais “clean”, mas menos informativo) ou com esses intervalos:
# Preparar uma paleta de cores condizente com a paleta usada no gráfico de barras empilhadas
paleta<-c("#D7191C", "#FDAE61", "#9C9C9C", "#ABDDA4", "#2B83BA")
model_data %>%
ggplot(aes(x=num, y=Probabilidades, group=Respostas, color=Respostas))+
geom_line()+geom_point()+
facet_wrap(~ordem)+
geom_hline(yintercept=0.5, color="grey", linetype="dashed")+
scale_y_continuous(breaks = seq(from = 0, to = 1.0, by = 0.1),
labels = scales::number_format(accuracy = 0.01))+
# scale_colour_manual(values=paleta,
# labels=c("Discordo_Totalmente", "Discordo", "Neutro", "Concordo", "Concordo_Totalmente"))+
labs(x = "Número da anáfora", y = "Probabilidades preditas", fill="Respostas")+
ggtitle("Previsão de probabilidades estimada pelo modelo de regressão ordinal")+
theme_classic()+
guides(colour = guide_legend(reverse=T)) # Apenas organizando a ordem da legenda.
model_data %>%
ggplot(aes(x=num, y=Probabilidades, group=Respostas, color=Respostas))+
geom_line(position = position_dodge(0.2))+
geom_point(position = position_dodge(0.2))+
geom_errorbar(aes(ymin=lower, ymax=upper),
width=0.0, position = position_dodge(0.2), alpha=0.3)+
facet_wrap(~ordem)+
scale_y_continuous(breaks = seq(from = 0, to = 1.0, by = 0.1),
labels = scales::number_format(accuracy = 0.01))+
scale_colour_manual(values=paleta,
labels=c("Discordo_Totalmente", "Discordo", "Neutro", "Concordo", "Concordo_Totalmente"))+
labs(x = "Número da anáfora", y = "Probabilidades preditas", fill="Respostas")+
ggtitle("Painel 2: Previsão de probabilidades estimada pelo modelo",
subtitle = "Linhas verticais indicam intervalos de credibilidade preditos.")+
theme_classic()+
guides(colour = guide_legend(reverse=T)) # Apenas organizando a ordem da legenda.Pronto, finalmente acabamos! O resultado final será composto pelos dois gráficos disponíveis no início desse post, colocados um abaixo do outro para facilitar a comparação entre os dados descritivos (Painel 1) e os dados inferenciais (Painel 2).