Começando do zero no PCIbex - Parte 02
Por Igor Costa (LAPAL/PUC-Rio) e Ana Paula Jakubów (LAPAL/PUC-Rio; UERJ)
Na parte 1 do nosso tutorial, que você pode acessar aqui, mostramos como começar do zero no PCIbex, criando uma página de instruções com um botão clicável e como inserir um único item experimental para um experimento de leitura automonitorada. O problema é que nunca temos um único item experimental, mas vários itens, de vários tipos diferentes. Nessa parte 2, então, vamos mostrar como usar a mesma estrutura básica que já aprendemos para, em vez de inserirmos item a item no código, buscarmos cada um dos itens em uma tabela.
Trabalhando com arquivos .csv
Antes de começarmos, você precisa saber o que é um arquivo .csv. Essa sigla significa “comma separated value”, ou seja, valores separados por vírgulas. Esse é um formato muito simples de armazenar dados, sobretudo dados numéricos, mas também muito eficaz. O motivo está na leveza do arquivo. Como o .csv é um formato de texto, ou seja, ele não tem nada além do texto e dos números que você inserir nele (não tem formatação, não tem cores, não tem qualquer tipo de destaque, não tem fórmulas, etc.), o arquivo final acaba sendo muito leve do ponto de vista computacional, de modo que tabelas gigantescas, com milhares ou até centenas de milhares de linhas, tenham apenas alguns poucos kilo bytes de dados. Esse é, portanto, o arquivo perfeito para usarmos em uma plataforma online como o PCIbex.
O lado negativo desse formato é que ele torna muito difícil a leitura humana do seu conteúdo. Em outras palavras, é ótimo para a máquina, mas pouco amigável para a gente - até que você se acostume a ele, claro.
No nosso caso, usaremos o .csv para criar uma tabela com informações sobre nossos estímulos experimentais - as frases que usaremos no experimento de leitura automonitorada.
Mas, afinal, como criar um arquivo .csv? Que programas você deve usar para isso? Criar uma tabela em formato .csv é muito simples: basta abrir um editor de textos (como o “Bloco de notas” ou o “WordPad”, ambos da Microsoft) e daí digitar os seus dados, sendo que cada coluna da tabela será separada por uma vírgula, como abaixo, onde temos uma tabela com 4 colunas e 5 linhas:
Coluna1,Coluna2,Coluna3,Coluna4
Dado1,Dado2,Dado3,Dado4
Dado5,Dado6,Dado7,Dado8
Dado9,Dado10,Dado11,Dado12
Dado13,Dado14,Dado15,Dado16.csv, mas por enquanto não faça isso, pois há algumas configurações que precisam ser feitas paras as coisas funcionarem direito no Excel.
Ah! Não coloque espaço entre os elementos depois da vírgula. Isso pode trazer alguns probleminhas.
Definindo um design experimental
Vamos começar com um experimento bem simples em que tenhamos 4 sentenças apenas, todas com verbos transitivos, mas nas quais o artigo que introduz o sujeito pode estar no singular ou no plural:
- A menina comeu o bolo.
- As menina comeu o bolo.
- O lobo mordeu a lebre.
- Os lobo mordeu a lebre.
Vamos dizer que queiramos uma design between subjects, ou seja, em que um grupo de participantes veja apenas a condição singular e outro veja apenas a condição plural. Vamos criar a seguinte tabela .csv para esses dados e vamos nomeá-la como “minhatabela.csv” (não se acanhe, você pode apenas copiar o código abaixo, colar no bloco de notas e salvar como “minhatabela.csv” simplesmente mudando o formato .txt que o Windows te apresenta como padrão para .csv).
Observe que a nossa tabelinha abaixo não tem acentos ou cedilhas ou qualquer coisa desse tipo. Se a sua tiver, é importante que você salve a sua planilha .csv com codificação UTF-8. Essa codificação apenas indica para o computador que seus dados têm acentos e cedilhas e outros sinais diacríticos. Para salvar seu documento com essa codificação, basta, no Blobo de Notas, selecionar em “codificação” a opção “UTF-8”:
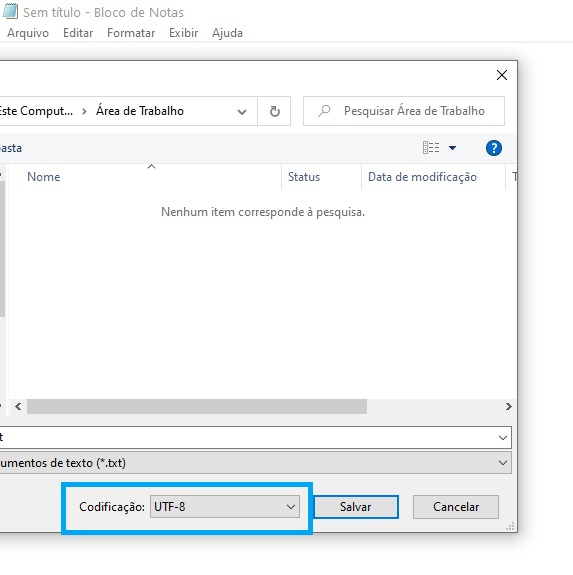
group,item,verbo,numero,frase
A,1,transitivo,sg,A menina comeu o bolo.
B,1,transitivo,pl,As menina comeu o bolo.
A,2,transitivo,sg,O lobo mordeu a lebre.
B,2,transitivo,pl,Os lobo mordeu a lebre.Do modo como essa tabela está organizada, o que acontecerá é o seguinte: um grupo de sujeitos verá as sentenças do tipo A, ou seja, as que estão no singular; e outro grupo verá as sentenças do tipo B, as que estão no plural. Se você quiser, pode pensar na coluna “group” como aquilo que chamamos de “listas”, sendo que cada sujeito será automaticamente colocado em uma das duas listas disponíveis. O item e o verbo não serão importantes agora, mas deixemo-los aí para facilitar a nossa vida mais adiante.
Agora que a nossa tabela está criada, você pode arrastar esse arquivo para a aba Resources do PCIbex (simplesmentes clique em cima do arquivo, segure e arraste que ele vai parar lá.) Se preferir, passe o mouse no sinal + ao lado de Resources; você verá uma opção chamada “upload from disk”. Ali você seleciona qual arquivo deseja importar para Resources.
Criando o nosso experimento
Para criar o experimento, vamos usar basicamente a estrutura que fizemos antes, com pequenas modificações. Abaixo está o código completo que usaremos:
PennController.ResetPrefix(null)
newTrial("meuexemplo",
defaultText
.center()
.print()
,
newText("Aperte a barra de espaço para ler as frases. <br><br> Seu tempo de leitura estará sendo medido.")
,
newText("<br>Vamos começar?")
,
newButton("meubotao", "Sim!")
.center()
.print()
.wait()
)
,
Template("minhatabela.csv",
exp => newTrial("minhasfrases",
newController("DashedSentence", {s: exp.frase})
.center()
.print()
.log()
.wait()
.remove()
)
)
Como você deve ter notado, o primeiro trial é idêntico ao da parte 1 do nosso tutorial. A mudança toda agora está no segundo trial. Vamos investigar o esqueleto desse código:
Template(
exp => newTrial(
newController()
.center()
.print()
.log()
.wait()
.remove()
)
)
As únicas novidades aí são Template e exp. O resto você já sabe o que é (se não sabe, volte à Parte 1). Vamos por partes:
Template("minhatabela.csv",
exp =>
Em Template, incluímos duas coisas: "minhatabela.csv" e exp. Logo, o que esse Template está fazendo é, em primeiro lugar, acessando a nossa tabela com as frases experimentais (esse nome colocado entre aspas tem de ser idêntico ao nome do arquivo que você salvou, incluisve com o .csv ao final) e atribuindo essa tabela ao objeto exp. O exp é uma variável, ou seja, é uma espécie de comando que nós mesmos criamos e, como nós mesmos criamos, podemos dar o nome que quisermos (na página do PCIbex, eles dão o nome de row. Você pode trocar pelo que quiser ou manter como está.). Essa variável contém (=>) tudo que está depois da setinha (o sinal de = seguido do sinal de maior >). Vamos à segunda parte então:
exp => newTrial("minhasfrases",
newController("DashedSentence", {s: exp.frase})
A nossa variável exp contém um newTrial, que recebeu o nome “minhasfrases” (você poderia dar qualquer nome aqui) e, como antes, dentro dele colocamos o controlador para DashedSentence. Dentro desse controlador, no entanto, fizemos uma coisa muito diferente, em vez de colocarmos a nossa sentença experimental depois de {s:, colocamos “exp.frase”. Lembre-se de que a última coluna da nossa tabela se chama justamente frase. Mas, afinal, o que o PCIbex está fazendo aqui? Simplemente dizendo: dentro do objeto exp (que é a tabela .csv), acesse a coluna frase (que contém as frases experimentais a serem apresentadas pelo controlador DashedSentence).
Feito isso, essa parte do código ficará assim:
Template("minhatabela.csv",
exp => newTrial("minhasfrases",
newController("DashedSentence", {s: exp.frase})
.center()
.print()
.log()
.wait()
.remove()
)
)
E seu experimento estará pronto para rodar. Como nós já definimos a coluna group, não precisamos fazer mais nada. O primeiro sujeito que fizer, fará as sentenças do grupo A e o segundo as do grupo B e assim sucessivamente para todos os sujeitos.
O resultados que serão recebidos estão abaixo (para o primeiro sujeito apenas):
# Last submission only; create an account for full results file
#
# Results on Sunday May 02 2021 16:42:49 UTC
# USER AGENT: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:88.0) Gecko/20100101 Firefox/88.0
# Design number was non-random = 2
#
# Columns below this comment are as follows:
# 1. Results reception time.
# 2. MD5 hash of participant's IP address.
# 3. Controller name.
# 4. Order number of item.
# 5. Inner element number.
# 6. Label.
# 7. Latin Square Group.
# 8. PennElementType.
# 9. PennElementName.
# 10. Parameter.
# 11. Value.
# 12. EventTime.
# 13. Comments.
1619973769,313362cc8a2fca017214b0da440b8033,PennController,0,0,meuexemplo,NULL,PennController,0,_Trial_,Start,1619973764745,NULL
1619973769,313362cc8a2fca017214b0da440b8033,PennController,0,0,meuexemplo,NULL,PennController,0,_Trial_,End,1619973765691,NULL
1619973769,313362cc8a2fca017214b0da440b8033,PennController,1,0,minhasfrases,NULL,PennController,1,_Trial_,Start,1619973765705,NULL
# 13. Reading time.
# 14. Newline?.
# 15. Sentence (or sentence MD5).
# 16. Comments.
1619973769,313362cc8a2fca017214b0da440b8033,PennController,1,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,1,A,1619973767629,319,false,A menina comeu o bolo.,Any addtional parameters were appended as additional columns
1619973769,313362cc8a2fca017214b0da440b8033,PennController,1,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,2,menina,1619973767629,256,false,A menina comeu o bolo.,Any addtional parameters were appended as additional columns
1619973769,313362cc8a2fca017214b0da440b8033,PennController,1,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,3,comeu,1619973767629,256,false,A menina comeu o bolo.,Any addtional parameters were appended as additional columns
1619973769,313362cc8a2fca017214b0da440b8033,PennController,1,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,4,o,1619973767629,255,false,A menina comeu o bolo.,Any addtional parameters were appended as additional columns
1619973769,313362cc8a2fca017214b0da440b8033,PennController,1,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,5,bolo.,1619973767629,257,false,A menina comeu o bolo.,Any addtional parameters were appended as additional columns
# 13. Comments.
1619973769,313362cc8a2fca017214b0da440b8033,PennController,1,0,minhasfrases,NULL,PennController,1,_Trial_,End,1619973767632,NULL
1619973769,313362cc8a2fca017214b0da440b8033,PennController,2,0,minhasfrases,NULL,PennController,2,_Trial_,Start,1619973767635,NULL
# 13. Reading time.
# 14. Newline?.
# 15. Sentence (or sentence MD5).
# 16. Comments.
1619973769,313362cc8a2fca017214b0da440b8033,PennController,2,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,1,O,1619973769412,256,false,O lobo morreu de fome.,Any addtional parameters were appended as additional columns
1619973769,313362cc8a2fca017214b0da440b8033,PennController,2,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,2,lobo,1619973769412,263,false,O lobo morreu de fome.,Any addtional parameters were appended as additional columns
1619973769,313362cc8a2fca017214b0da440b8033,PennController,2,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,3,morreu,1619973769412,232,false,O lobo morreu de fome.,Any addtional parameters were appended as additional columns
1619973769,313362cc8a2fca017214b0da440b8033,PennController,2,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,4,de,1619973769412,257,false,O lobo morreu de fome.,Any addtional parameters were appended as additional columns
1619973769,313362cc8a2fca017214b0da440b8033,PennController,2,0,minhasfrases,NULL,Controller-DashedSentence,DashedSentence,5,fome.,1619973769412,247,false,O lobo morreu de fome.,Any addtional parameters were appended as additional columns
# 13. Comments.
1619973769,313362cc8a2fca017214b0da440b8033,PennController,2,0,minhasfrases,NULL,PennController,2,_Trial_,End,1619973769415,NULLBrincando com os designs experimentais
Agora que você já sabe como incluir os itens, você pode começar a fazer brincadeiras simples com o seu desenho experimental. Imagine, por exemplo, que você tenha três conjuntos de frases e não mais dois, como antes. Você pode incluí-las facilmente no seu experimento (sem qualquer alteração no código), apenas acrescentando essas sentenças na tabela .csv:
group,item,verbo,numero,frase
A,1,transitivo,sg,A menina comeu o bolo.
B,1,transitivo,pl,As menina comeu o bolo.
C,1,transitivo,pl red,As meninas comeram o bolo.
A,2,transitivo,sg,O lobo mordeu a lebre.
B,2,transitivo,pl,Os lobo mordeu a lebre.
C,2,transitivo,pl red,Os lobos morderam a lebre.Ou você pode ter, digamos, um outro tipo de verbo, como “intransitivo”. Repare que mudamos a etiqueta das sentenças para algo mais mnemônico. Nesse caso, teremos 4 grupos de sujeitos, cada qual associado a uma das 4 condições experimentais:
group,item,verbo,numero,frase
t_sg,1,transitivo,sg,A menina comeu o bolo.
t_pl,1,transitivo,pl,As menina comeu o bolo.
i_sg,1,intransitivo,sg,A menina dormiu cedo.
i_pl,1,intransitivo,pl,As menina dormiu cedo.
t_sg,2,transitivo,sg,O lobo mordeu a lebre.
t_pl,2,transitivo,pl,Os lobo mordeu a lebre.
i_sg,2,intransitivo,sg,O lobo morreu de fome.
i_pl,2,intransitivo,pl,Os lobo morreu de fome.